開啟百萬上下文平民化時代 DeepSeek V4因性能躍升與定價革命再受矚目
鉅亨網新聞中心
曾以 R1 模型撼動市場的杭州新創公司 DeepSeek,周五 (24 日) 正式推出並同步開源了全新的 DeepSeek-V4 系列預覽版。據陸媒《華爾街見聞》報導,這款模型在百萬級上下文處理、Agent(智慧體) 能力、世界知識以及推理性能上均實現了顯著進步,被社群譽為「GPT-5.5 級別」的震撼時刻,甚至在程式碼能力上直逼甚至超越了部分頂級閉源模型。

程式碼與 Agent 能力的跨越式突破
DeepSeek-V4 系列包含兩個版本:總參數達 1.6 兆 (激活參數 49B) 的旗艦版 V4-Pro,以及專為高效率設計、總參數 2840 億 (激活參數 13B) 的 V4-Flash。兩款模型均標配 100 萬 token 的超長上下文窗口。
在第三方評測中,V4 展示了驚人的實力:
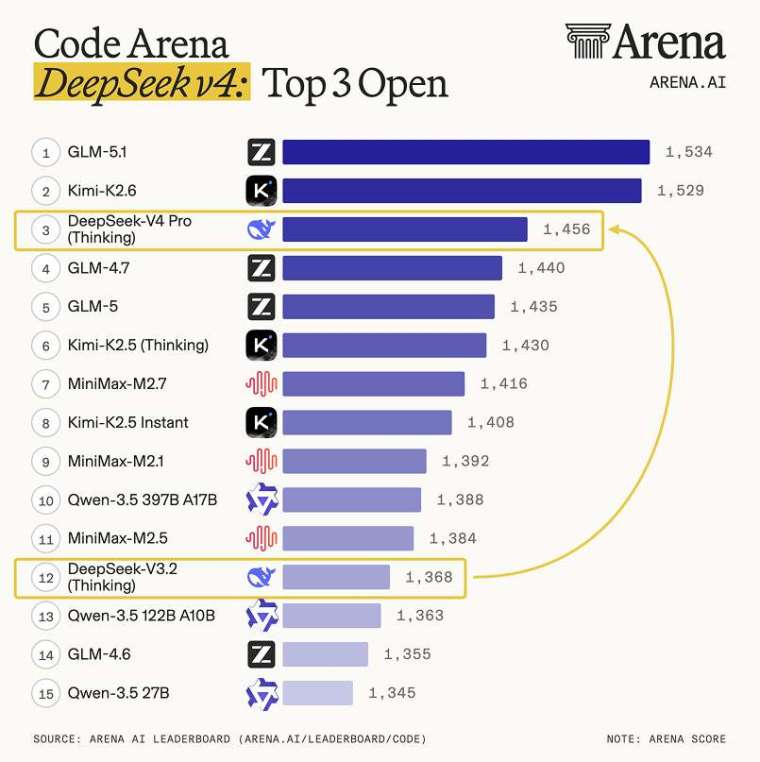
- 程式碼能力: 評測平台 Arena.ai 將 V4-Pro(思考模式) 列為開源模型第 3 位、綜合排名第 14 位,被定性為相較於前代 V3.2 的「重大飛躍」。另一家評測方 Vals AI 更指出,V4 在 Vibe Code Benchmark 中以壓倒性優勢奪冠,擊敗了 Gemini 3.1 Pro,且其程式碼性能較上代躍升約 10 倍。
- Agent 能力: DeepSeek 官方表示,V4 在 Agentic Coding(智慧體編程) 領域已達到開源界頂尖水準。在公司內部測試中,其編程體驗優於 Claude Sonnet 4.5,交付質量接近 Opus 4.6 的非思考模式。
- 邏輯推理與知識: 在數學、STEM 及競賽級程式碼測試中,V4-Pro 超越了包括 Kimi K2.6 Thinking 在內的所有已公開開源模型,世界知識儲備也僅稍遜於頂級閉源模型 Gemini-Pro-3.1。
三大神技重塑長上下文效率
DeepSeek-V4 的強大源於底層架構的結構性創新,尤其是解決了傳統注意力機制在長文本場景下算力與顯存需求飆升的痛點。其核心技術包括:
- 混合注意力機制 (CSA + HCA): 這是 V4 最核心的創新。CSA(壓縮稀疏注意力) 以較低倍率壓縮 KV 緩存並結合稀疏檢索,確保中段細節;HCA(重度壓縮注意力) 則以極高倍率 (如 128 倍) 壓縮信息,專注全局邏輯。這種「長短結合」的策略,使模型在處理百萬 token 時,單 token 推理計算量僅為前代的 27%,KV 緩存占用縮減至 10%。
- 流形約束超連接 (mHC): 升級傳統的殘差連接,將信號傳播約束在穩定流形上,確保深層網路的穩定性與表達力。
- Muon 最佳化器: 引入全新的最佳化技術,使兆級參數模型的訓練過程收斂更快且更穩定。
此外,V4 採用了 On-Policy Distillation(OPD) 技術,透過蒸餾多個領域專家模型來提升學生模型的表現,並引入 Generative Reward Model(GRM) 讓模型能自我評核與優化。
定價革命:以 1% 的價格撼動市場
DeepSeek 再次展現了極致的成本控制能力,其定價策略對開發者極具殺傷力:
- V4-Flash: 輸出價格僅為 每百萬 token 0.28 美元。這比 OpenAI 的 GPT-5.4 Nano 更低,且僅約為 Claude Opus 4.7 價格的 1%。
- V4-Pro: 輸出價格為 3.48 美元,遠低於 Claude Opus 的 25 美元及 GPT-5.4 的 15 美元,是目前前沿大模型中成本最低的選項之一。
DeepSeek 更暗示,隨著下半年國產算力硬體 (如昇騰 950) 的大規模上市,V4-Pro 的價格仍有進一步下調的空間。
算力適配與開源影響
值得注意的是,DeepSeek-V4 是全球首個在 國產算力底座 (如華為昇騰 NPU) 上完成訓練與推理的兆參數級模型,實現了 1.50 至 1.73 倍的加速比。雖然目前昇騰適配代碼尚未完全開源,但寒武紀等平台已透過 vLLM 框架完成適配並開源至 GitHub。

儘管多數評論極為正面,甚至有網友戲稱「GPT-5.5 對不起,DeepSeek V4 才是新的震撼」,但也有部分用戶 (如 Michael Anti) 認為 V4-Flash 在實際體驗上並未顯著超越成熟的 V3.2,升級感有限。對此,官方態度保持克制,坦言在知識與推理上與最先進閉源系統仍有約 3 到 6 個月的差距。
DeepSeek-V4 的發布標誌著百萬級長上下文已成為標配,並將 Agent 能力推向新高度。開發者即日起可透過 API 接入 deepseek-v4-pro 或 deepseek-v4-flash。舊有的 deepseek-chat 與 deepseek-reasoner 名稱將作為過渡,預計於 2026 年 7 月 24 日正式停用。
- 講座
- 公告
上一篇
下一篇