鉅亨網新聞中心
矽谷近日的 AI 重點聚焦在中國發展的 DeepSeek,不過,一家美國公司在中國過年期間,也發表了新的模型,並聲稱在多項 AI 基準測試中超越了 DeepSeek V3 和 GPT-4o。
Allen Institute for AI (AI2) 發表 Tülu 3 系列模型,Tülu 3 系列包括多個版本, 8B、70B 和最新的 405B,其中 Tülu 3 405B 是目前最大規模的開源 AI 語言模型之一,並且首次應用了完整開放的後訓練 (Post-Training) 方法。
根據 Ai2 的內部測試,Ai2 的模型名為 Tulu 3 405B,在某些 AI 基準測試中也擊敗了 OpenAI 的 GPT-4o。此外,與 GPT-4o(甚至 DeepSeek V3) 不同,Tulu 3 405B 是開源的,這意味著從頭開始複製它所需的所有元件都是免費提供並獲得許可的。
Ai2 的發言人表示,該實驗室認為 Tulu 3 405B「凸顯了美國引領全球一流生成式 AI 模型開發的潛力」。
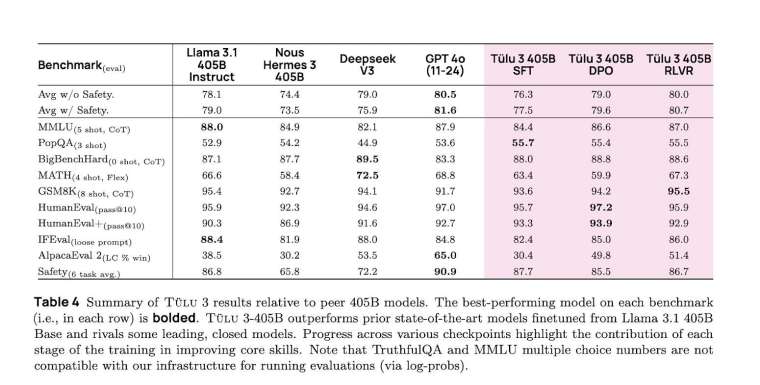
據《techcrunch》等媒體報導, Tülu 3 405B 有幾個關鍵特色與表現:
性能超越:Tülu 3 405B 在多個基準測試中表現優異,尤其是在 PopQA (針對來自維基百科的事實資訊)、GSM8K (針對計算能力)、以及 HumanEval+ (針對程式碼生成能力)。Ai2 聲稱,該模型在 PopQA 測試中,不僅超越了 DeepSeek V3 和 GPT-4o,甚至超越了 Meta 的 Llama 3.1 405B 模型。
開源性質:與 GPT-4o 和 DeepSeek V3 不同,Tülu 3 405B 是開源的,這意味著所有用於從頭開始複製該模型的必要組件都是免費提供且許可寬鬆的。這對於促進 AI 研究和開發社群的合作具有重要意義。
訓練方法:Ai2 採用了一系列創新的訓練方法,包括:
模型規模:Tülu 3 405B 模型包含 4050 億個參數,需要 256 個 GPU 並行運行才能進行訓練。參數數量大致對應於模型的解決問題能力,通常參數較多的模型性能會更好。
基準測試比較:儘管 Tülu 3 405B 在某些基準測試中表現出色,但在其他測試中,如 BigBenchHard 和 MATH,DeepSeek 則在推理和數學能力上表現更佳。這表明不同的模型在不同任務和領域具有不同的優勢。
Ai2 強調 Tülu 3 405B 的發佈是美國在生成式 AI 模型全球開發中潛力的體現。該模型不僅是技術上的突破,更展現了美國可以透過開源 AI 模式引領競爭,而不依賴於大型科技公司。Tülu 3 405B 的推出標誌著 AI 開發的重要時刻,並為其他 AI 研究人員和開發者提供了可參考的範例。
Tülu 3 405B 的程式碼可在 GitHub 和 AI 開發平台 Hugging Face 上取得,並且可以透過 Ai2 的聊天機器人網頁應用程式進行測試。
上一篇
下一篇
