BlockBeats 律動財經
ChatGPT 等基於自然語言處理技術的聊天 AI,就短期來看亟需要解決的法律合規問題主要有三個:
其一,聊天 AI 提供的答覆的知識產權問題,其中最主要的合規難題是聊天 AI 產出的答覆是否產生相應的知識產權?是否需要知識產權授權?
其二,聊天 AI 對巨量的自然語言處理文本(一般稱之為語料庫)進行數據挖掘和訓練的過程是否需要獲得相應的知識產權授權?
其三,ChatGPT 等聊天 AI 的回答是機制之一是通過對大量已經存在的自然語言文本進行數學上的統計,得到一個基於統計的語言模型,這一機制導致聊天 AI 很可能會「一本正經的胡說八道」,進而導致虛假資訊傳播的法律風險,在這一技術背景下,如何儘可能降低聊天 AI 的虛假資訊傳播風險?
總體而言,目前我國對於人工智慧立法依然處在預研究階段,還沒有正式的立法計劃或者相關的動議草案,相關部門對於人工智慧領域的監管尤為謹慎,隨著人工智慧的逐步發展,相應的法律合規難題只會越來越多。

ChatGPT 本質上是自然語言處理技術發展的產物,本質上依然僅是一個語言模型。
2023 開年之初全球科技巨頭微軟的巨額投資讓 ChatGPT 成為科技領域的「頂流」並成功出圈。隨著資本市場 ChatGPT 概念板塊的大漲,國內眾多科技企業也着手布局這一領域,在資本市場熱捧 ChatGPT 概念的同時,作為法律工作者,我們不禁要評估 ChatGPT 自身可能會帶來哪些法律安全風險,其法律合規路徑何在?
在討論 ChatGPT 的法律風險及合規路徑之前,我們首先應當審視 ChatGPT 的技術原理——ChatGPT 是否如新聞所言一樣,可以給提問者任何其想要的問題?
在颯姐團隊看來,ChatGPT 似乎遠沒有部分新聞所宣傳的那樣「神」——一句話總結,其僅僅是 Transformer 和 GPT 等自然語言處理技術的集成,本質上依然是一個基於神經網路的語言模型,而非一項「跨時代的 AI 進步」。
前面已經提到 ChatGPT 是自然語言處理技術發展的產物,就該技術的發展史來看,其大致經歷了基於語法的語言模型——基於統計的語言模型——基於神經網路的語言模型三大階段,ChatGPT 所在的階段正是基於神經網路的語言模型階段,想要更為直白地理解 ChatGPT 的工作原理及該原理可能引發的法律風險,必須首先闡明的就是基於神經網路的語言模型的前身——基於統計的語言模型的工作原理。
基於統計的語言模型階段,AI 工程師通過對巨量的自然語言文本進行統計,確定詞語之間先後連結的機率,當人們提出一個問題時,AI 開始分析該問題的構成詞語共同組成的語言環境之下,哪些詞語搭配是高機率的,之後再將這些高機率的詞語拼接在一起,返回一個基於統計學的答案。可以說這一原理自出現以來就貫穿了自然語言處理技術的發展,甚至從某種意義上說,之後出現的基於神經網路的語言模型亦是對基於統計的語言模型的修正。
舉一個容易理解的例子,颯姐團隊在 ChatGPT 聊天框中輸入問題「大連有哪些旅遊勝地?」如下圖所示:
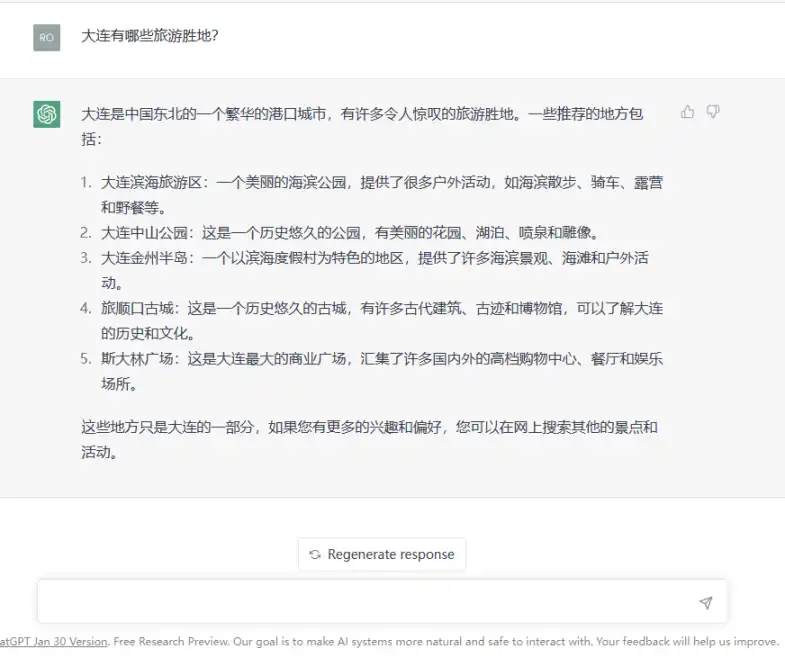
AI 第一步會分析問題中的基本語素「大連、哪些、旅遊、勝地」,再在已有的語料庫中找到這些語素所在的自然語言文本集合,在這個集合中找尋出現機率最多的搭配,再將這些搭配組合以形成最終的答案。如 AI 會發現在「大連、旅遊、勝地」這三個詞高機率出現的語料庫中,有「中山公園」一詞,於是就會返回「中山公園」,又如「公園」這個詞與花園、湖泊、噴泉、雕像等詞語搭配的機率最大,因此就會進一步返回「這是一個歷史悠久的公園,有美麗的花園、湖泊、噴泉和雕像。」
換言之,整個過程都是基於 AI 背後已有的自然語言文本資訊(語料庫)進行的機率統計,因此返回的答案也都是「統計的結果」,這就導致了 ChatGPT 在許多問題上會「一本正經的胡說八道」。如剛才的這個問題「大連有哪些旅遊勝地」的回答,大連雖然有中山公園,但是中山公園中並沒有湖泊、噴泉和雕像。大連在歷史上的確有「斯大林廣場」,但是斯大林廣場自始至終都不是一個商業廣場,也沒有任何購物中心、餐廳和娛樂場所。顯然,ChatGPT 返回的資訊是虛假的。

雖然上個部分我們直白的講明了基於統計的語言模型的弊端,但 ChatGPT 畢竟已經是對基於統計的語言模型大幅度改良的基於神經網路的語言模型,其技術基礎 Transformer 和 GPT 都是最新一代的語言模型,ChatGPT 本質上就是將海量的數據結合表達能力很強的 Transformer 模型結合,從而對自然語言進行了一個非常深度的建模,返回的語句雖然有時候是「胡說八道」,但乍一看還是很像「人類回復的」,因此這一技術在需要海量的人機交互的場景下具有廣泛的應用場景。
就目前來看,這樣的場景有三個:
其一,搜尋引擎;
其二,銀行、律所、各類仲介機構、商場、醫院、政府政務服務平台中的人機交互機制,如上述場所中的客訴系統、導診導航、政務諮詢系統;
第三,智能汽車、智能家居(如智能音箱、智能燈光)等的交互機制。
結合 ChatGPT 等 AI 聊天技術的搜尋引擎很可能會呈現出傳統搜尋引擎為主 + 基於神經網路的語言模型為輔的途徑。目前傳統的搜尋巨頭如谷歌和百度均在基於神經網路的語言模型技術上有著深厚的積累,譬如谷歌就有與 ChatGPT 相媲美的 Sparrow 和 Lamda,有著這些語言模型的加持,搜尋引擎將會更加「人性化」。
ChatGPT 等 AI 聊天技術運用在客訴系統和醫院、商場的導診導航以及政府機關的政務諮詢系統中將大幅度降低相關單位的人力資源成本,節約溝通時間,但問題在於基於統計的回答有可能產生完全錯誤的內容回復,由此帶來的風控風險恐怕還需要進一步評估。
相比於上述兩個應用場景,ChatGPT 應用在智能汽車、智能家居等領域成為上述設備的人機交互機制的法律風險則要小很多,因為這類領域應用環境較為私密,AI 反饋的錯誤內容不至於引起大的法律風險,同時這類場景對內容準確性要求不高,商業模式也更為成熟。

和許多新興技術一樣,ChatGPT 所代表的自然語言處理技術也面臨着「科林格里奇窘境(Collingridge dilemma)」這一窘境包含了資訊困境與控制困境,所謂資訊困境,即一項新興技術所帶來的社會後果不能在該技術的早期被預料到;所謂控制困境,即當一項新興技術所帶來的不利的社會後果被發現時,技術卻往往已經成為整個社會和經濟結構的一部分,致使不利的社會後果無法被有效控制。
目前人工智慧領域,尤其是自然語言處理技術領域正在快速發展階段,該技術很可能會陷入所謂的「科林格里奇窘境」,與此相對應的法律監管似乎並未「跟得上步伐」。我國目前尚無國家層面上的人工智慧產業立法,但地方已經有相關的立法嘗試。就在去年 9 月,深圳市公布了全國收不人工智慧產業專項立法《深圳經濟特區人工智慧產業促進條例》,緊接着上海也通過了《上海市促進人工智慧產業發展條例》,相信不久之後各地均會出台類似的人工智慧產業立法。
在人工智慧的倫理規制方面,國家新一代人工智慧治理專業委員會亦在 2021 年發布了《新一代人工智慧倫理規範》,提出將倫理道德融入人工智慧研發和應用的全生命周期,或許在不久的將來,類似阿西莫夫小說中的「機器人三定律」將成為人工智慧領域監管的鐵律。
將目光由宏觀轉向微觀,拋開人工智慧產業的整體監管圖景和人工智慧倫理規制問題,ChatGPT 等 AI 聊天基礎存在的現實合規問題也急需重視。
這其中較為棘手的是 ChatGPT 回復的虛假資訊問題,正如本文在第二部分提及的,ChatGPT 的工作原理導致其回復可能完全是「一本正經的胡說八道」,這種看似真實實則離譜的虛假資訊具有極大的誤導性。當然,像對「大連有哪些旅遊勝地」這類問題的虛假回復可能不會造成嚴重後果,但倘若 ChatGPT 應用到搜尋引擎、客訴系統等領域,其回復的虛假資訊可能造成極為嚴重的法律風險。
實際上這樣的法律風險已經出現,2022 年 11 月幾乎與 ChatGPT 同一時間上線的 Meta 服務科研領域的語言模型 Galactica 就因為真假答案混雜的問題,測試僅僅 3 天就被用戶投訴下線。在技術原理無法短時間突破的前提下,倘若將 ChatGPT 及類似的語言模型應用到搜尋引擎、客訴系統等領域,就必須對其進行合規性改造。當檢測到用戶可能詢問專業性問題時,應當引導用戶諮詢相應的專業人員,而非在人工智慧處尋找答案,同時應當顯著提醒用戶聊天 AI 返回的問題真實性可能需要進一步驗證,以最大程度降低相應的合規風險。
當將目光由宏觀轉向微觀時,除了 AI 回復資訊的真實性問題,聊天 AI 尤其是像 ChatGPT 這樣的大型語言模型的知識產權問題亦應該引起合規人員的注意。
首先的合規難題是「文本數據挖掘」是否需要相應的知識產權授權問題。正如前文所指明的 ChatGPT 的工作原理,其依靠巨量的自然語言本文(或言語料庫),ChatGPT 需要對語料庫中的數據進行挖掘和訓練,ChatGPT 需要將語料庫中的內容複製到自己的數據庫中,相應的行為通常在自然語言處理領域被稱之為「文本數據挖掘」。當相應的文本數據可能構成作品的前提下,文本數據挖掘行為是否侵犯複製權當前仍存在爭議。
在比較法領域,日本和歐盟在其著作權立法中均對合理使用的範圍進行了擴大,將 AI 中的「文本數據挖掘」增列為一項新的合理使用的情形。雖然 2020 年我國著作權法修法過程中有學者主張將我國的合理使用制度由「封閉式」轉向「開放式」,但這一主張最後並未被採納,目前我國著作權法依舊保持了合理使用制度的封閉式規定,僅著作權法第二十四條規定的十三中情形可以被認定為合理使用,換言之,目前我國著作權法並未將 AI 中的「文本數據挖掘」納入到合理適用的範圍內,文本數據挖掘在我國依然需要相應的知識產權授權。
其次的合規難題是 ChatGPT 產生的答覆是否具有獨創性?對於 AI 生成的作品是否具有獨創性的問題,颯姐團隊認為其判定標準不應當與現有的判定標準有所區別,換言之,無論某一答覆是 AI 完成的還是人類完成的,其都應當根據現有的獨創性標準進行判定。其實這個問題背後是另一個更具有爭議性的問題,如果 AI 生成的答覆具有獨創性,那麼著作權人可以是 AI 嗎?顯然,在包括我國在內的大部分國家的知識產權法律下,作品的作者僅有可能是自然人,AI 無法成為作品的作者。
最後,ChatGPT 倘若在自己的回覆中拼接了第三方作品,其知識產權問題應當如何處理?颯姐團隊認為,如果 ChatGPT 的答覆中拼接了語料庫中擁有著作權的作品(雖然依據 ChatGPT 的工作原理,這種情況出現的機率較小),那麼按照中國現行的著作權法,除非構成合理使用,否則非必須獲得著作權人的授權後才可以複製。

暢行幣圈交易全攻略,專家駐群實戰交流
▌立即加入鉅亨買幣實戰交流 LINE 社群(點此入群)
不管是新手發問,還是老手交流,只要你想參與加密貨幣現貨交易、合約跟單、合約網格、量化交易、理財產品的投資,都歡迎入群討論學習!
上一篇
下一篇