鉅亨網編譯鍾詠翔
在百度 (BIDU-US) 創辦人李彥宏表示旗下大模型產品「文心一言」「母本」將迎來 3.5 版本(ERNIE 3.5)後,內部人士在周二(20 日)表示,文心大模型 3.5 版本已內測應用,且實測得分超越 ChatGPT。
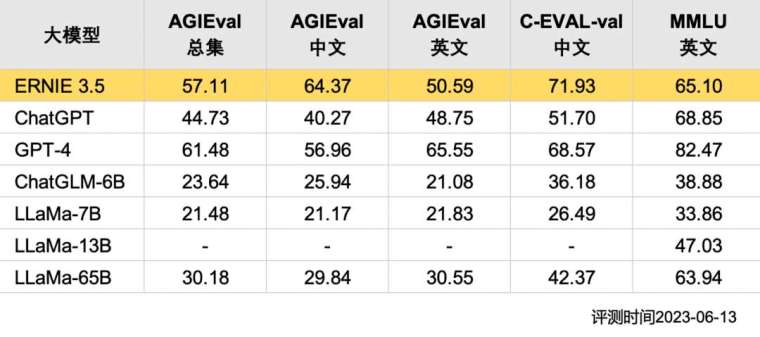
據《中國科學報》報導,在 AGIEval、C-Eval 等中英文權威測試集和 MMLU 英文權威測試集中,國產文心大模型 3.5 的得分超過 ChatGPT、LLaMa、ChatGLM 等其他大模型,在中文評測項中超越了 GPT-4。測試日期為 6 月 13 日。
在中文 AGIEval 評測中,文心大模型 3.5 得分為 64.37,遠超 ChatGLM-6B、LLaMa-7B、LLaMa-13B、LLaMa-65B,同時還超過 ChatGPT 的 40.27 分和 GPT-4 的 56.96 分,勇奪第一。
在 AGIEval 評測英文部分,GPT-4 的得分為 65.55,居於首位,文心大模型 3.5 為 50.59 分,僅次於 GPT-4。ChatGPT 的得分為 48.75 分。
在中文 C-Eval 評測中,文心大模型 3.5 測出 71.93,得分最高,不僅高於 ChatGPT 的 51.70 分,也略高於 GPT-4 的 68.57 分。
在英文 MMLU 測試中,GPT-4 和 ChatGPT 的表現較好,分別以 82.47 分和 68.85 分領先其他大模型。文心大模型 3.5 的得分為 65.10,優於 LLaMa-65B、LLaMa-13B、LLaMa-7B、ChatGLM-6B 等模型。
從上述評測得分來看,文心大模型 3.5 版的中文能力突出,甚至有超出 GPT-4 的表現;綜合能力稍遜 GPT-4,但文心大模型 3.5 已經在評測中超過 ChatGPT,遠遠領先於其他開源大模型。
儘管市面上有多個大模型橫空出世,但大模型研發門檻高、難度大、投入高,依賴算力、數據等綜合支撐的現實不容忽視。在大模型產業化的路上,中國企業如何在大模型發展過程中發揮優勢,加速縮小差距?
中國工程院院士鄔賀銓曾表示,中國企業在獲得中文語料和對中國文化理解方面比外國企業強,中國製造業門類最全,具有面向實體產業訓練產業 AIGC 的有利條件,且中國在算力方面已具有較好基礎。
以百度文心大模型 3.5 為例,與 3.0 版本相比,透過各項算法和數據強化,尤其是百度首創的知識增強和檢索增強技術,新版本文心大模型的各項能力均有明顯提升。
創新工場董事長李開復也曾說:「中國擁有豐富的中文語料和龐大的市場,通過發展 AI 大模型,中國可以推動創新產業的發展,實現科技與經濟的雙重紅利。而且中國擁有龐大基數的年輕工程師和最堅韌的企業家,為發展 AI 大模型提供了強大的人才支持,技術領先、策略靈活、市場反應快、能打硬仗、落地執行力強,將是中國大模型公司的成功關鍵。」
上一篇
下一篇
